
Database Performance
May 3, 2019
Here is a summary of relevant statements from “Use the index, Luke”, pertaining to database indexing.
Preface
- The separation of concerns—what is needed versus how to get it—works remarkably well in SQL, but it is still not perfect. The abstraction reaches its limits when it comes to performance.
- It turns out that the only thing developers need to learn is how to index.
- This book covers everything developers need to know about indexes—and nothing more. To be more precise, the book covers the most important index type only: the B-tree index.
Anatomy of an SQL Index
- A database index is more complex than a printed directory because it undergoes constant change.
- It must process insert, delete and update statements immediately, keeping the index order without moving large amounts of data.
- The database combines two data structures to meet the challenge: a doubly linked list and a search tree.
The Index Leaf Nodes
- The primary purpose of an index is to provide an ordered representation of the indexed data. It is, however, not possible to store the data sequentially because an insert statement would need to move the following entries to make room for the new one. Moving large amounts of data is very time-consuming so the insert statement would be very slow. The solution to the problem is to establish a logical order that is independent of physical order in memory.
- The logical order is established via a doubly linked list.
- Databases use doubly linked lists to connect the so-called index leaf nodes. Each leaf node is stored in a database block or page; that is, the database’s smallest storage unit. The database uses the space in each block to the extent possible and stores as many index entries as possible in each block.
The Search Tree (B-Tree) Makes the Index Fast
- A database needs a second structure to find the entry among the shuffled pages/blocks quickly: a balanced search tree—in short: the B-tree.
- The root and branch nodes support quick searching among the leaf nodes.
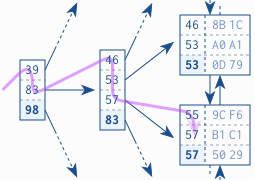
- The figure shows a B-tree. Each branch node entry corresponds to the biggest value in the respective leaf node. The figure also illustrates a search for the key “57”. The tree traversal starts at the root node on the left-hand side. Each entry is processed in ascending order until a value is greater than or equal to (>=) the search term (57). In the figure it is the entry 83. The database follows the reference to the corresponding branch node and repeats the procedure until the tree traversal reaches a leaf node.
- The tree depth grows very slowly compared to the number of leaf nodes. Real world indexes with millions of records have a tree depth of four or five. A tree depth of six is hardly ever seen.