
Can LLM agents analyze unstructured data?
LLMs aren’t great at analytics. If we upload structured CSV to Claude and ask it to “count the number of rows in this file”, it’s frequently incorrect. If the CSV is unstructured, the accuracy is even worse as the LLM struggles with noisy data. LLMs also have limited context windows and a few thousand rows can exceed its capabilities.
I wanted to dive a little deeper to learn what would be necessary for LLMs to get better and analyzing unstructured data for analytics queries. My goal was to analyze a few unstructured rows and ask aggregation questions over these rows.
Initially I tested a RAG architecture. In this approach, the documents were first chunked and stored in a special type of database called a vector database. I used Postgres with Pgvector extension. I then created an agentic app that could query the vector DB to execute semantic search and reason about the results. Semantic search is when a user can query similar concepts (see image below).
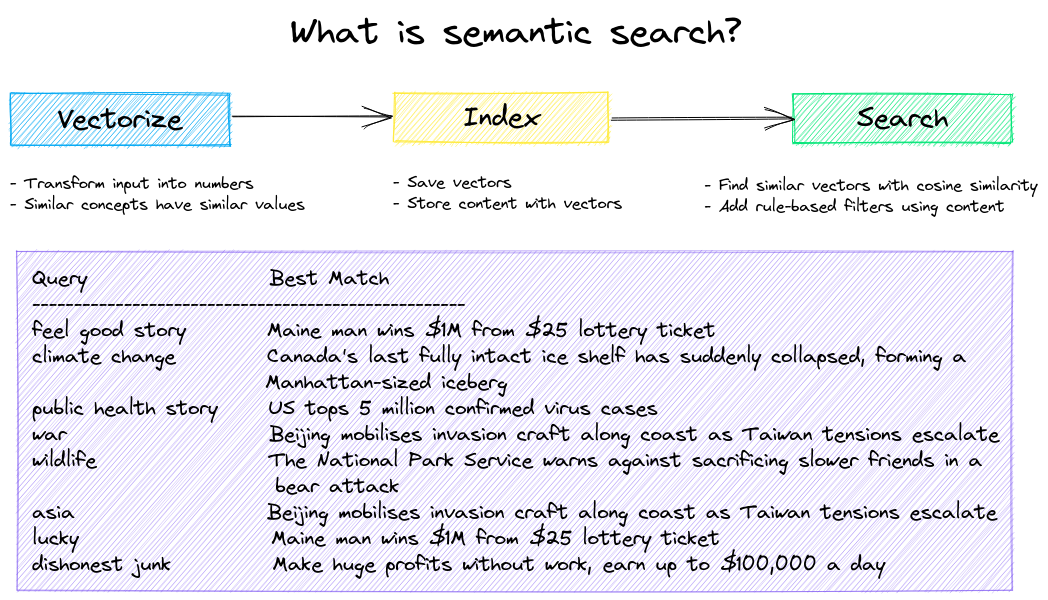
I found that the vector DBs require a lot of hardcoded tuning specific to the type of data being stored e.g., size of chunk, chunk overlap, embedding algorithm. However they can be effective for top-k queries compared to keyword search.
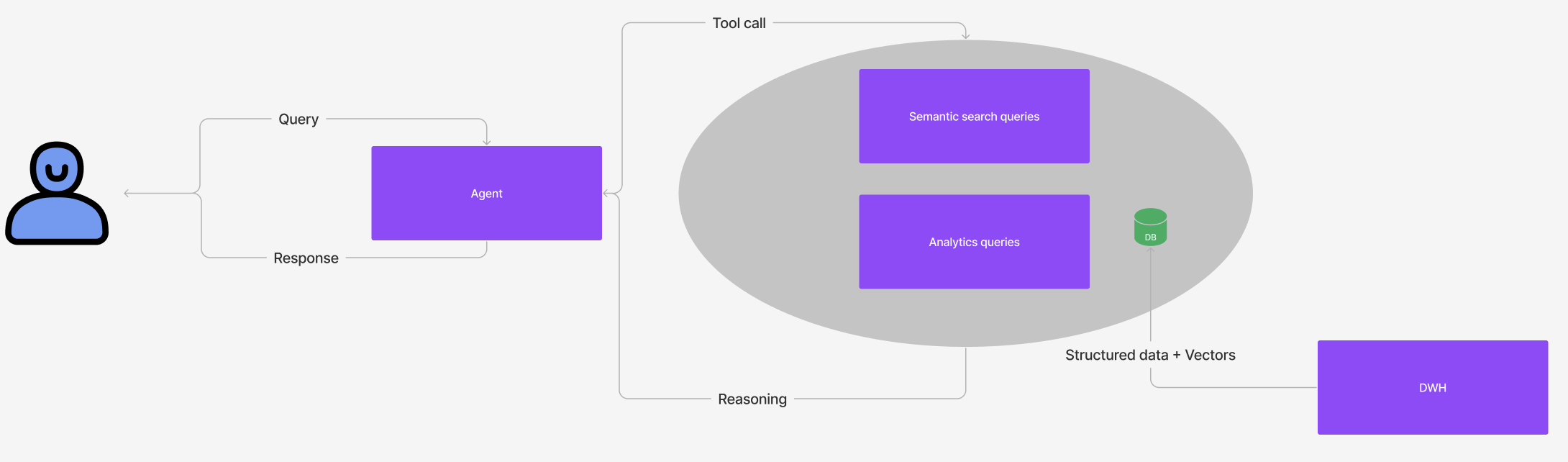 Next I updated the agentic app to additionally be able to query structured and clean SQL data (see image above). It was clever enough to search the vector DB to find similar concepts/keywords and then run multiple queries against structured SQL data and finally sum up the results via a sum function (see image below). It was exciting to see it chain these functions! However it became clear to me that data cleaning and de-noising were necessary in order for this approach to work.
Next I updated the agentic app to additionally be able to query structured and clean SQL data (see image above). It was clever enough to search the vector DB to find similar concepts/keywords and then run multiple queries against structured SQL data and finally sum up the results via a sum function (see image below). It was exciting to see it chain these functions! However it became clear to me that data cleaning and de-noising were necessary in order for this approach to work.
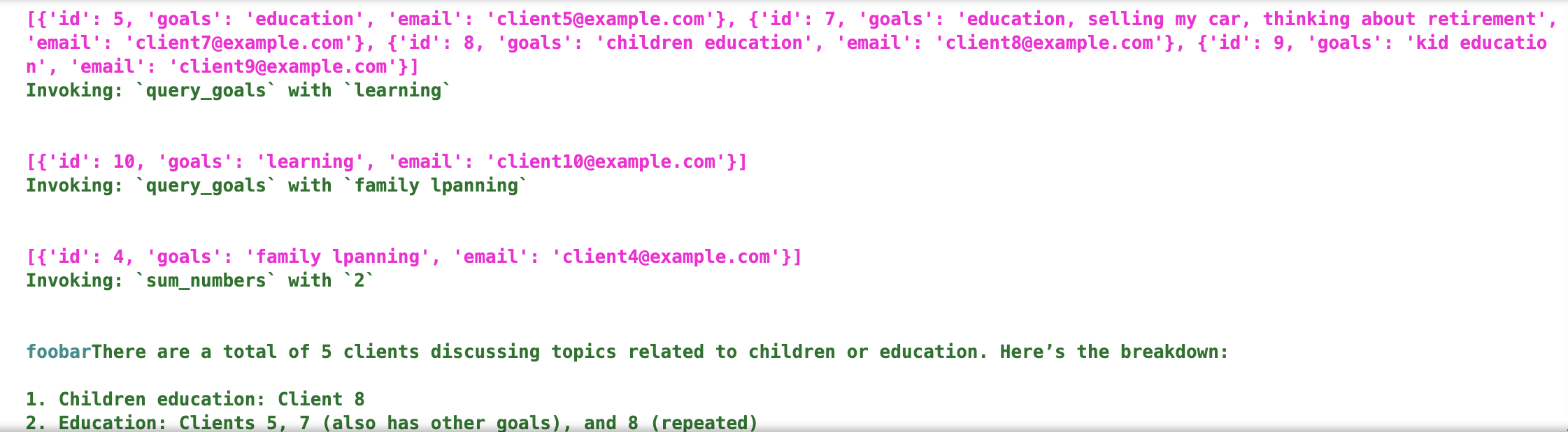
Is there a general-pupose way for LLMs to run accurate analytics queries over unstructured data? I think it’s a case of “garbage in, garbage out”. We have to clean the data first or ask the LLM to clean it up before any analysis via a prompt. It’s also important to tune the prompt for a specific set of analytics queries. However, I can imagine a general purpose product (e.g., claude desktop) that is outfitted with various MCP helpers to clean and analyze unstructured text, especially if the data is not at a “big data” scale.