
Developer Experience and Knowledge Graphs
I attended the Future of Developer Experience conference yesterday at OneEleven, a startup accelerator.
 The first speakers were Deskree, a startup that built a product called Tetrix. Their product analyzes your repos and AWS logs and metrics. It then builds a knowledge graph and enables your favorite IDE to query this data.
The first speakers were Deskree, a startup that built a product called Tetrix. Their product analyzes your repos and AWS logs and metrics. It then builds a knowledge graph and enables your favorite IDE to query this data.
Knowledge graphs
I took some time to understand how these knowledge graphs work. In a traditional RAG (retrieval augmented generation), a special type of database called a vector database is used. Unstructured data like your documents are embedded into vectors using LLMs and stored. When a user submits a query, this DB is queried and the output is passed to an LLM to produce an answer. From my past experiments, the vector DB needs a lot of tuning based on the domain of the data you’re analyzing and query results cannot be explained. They’re not great for answering complex questions across multiple documents.
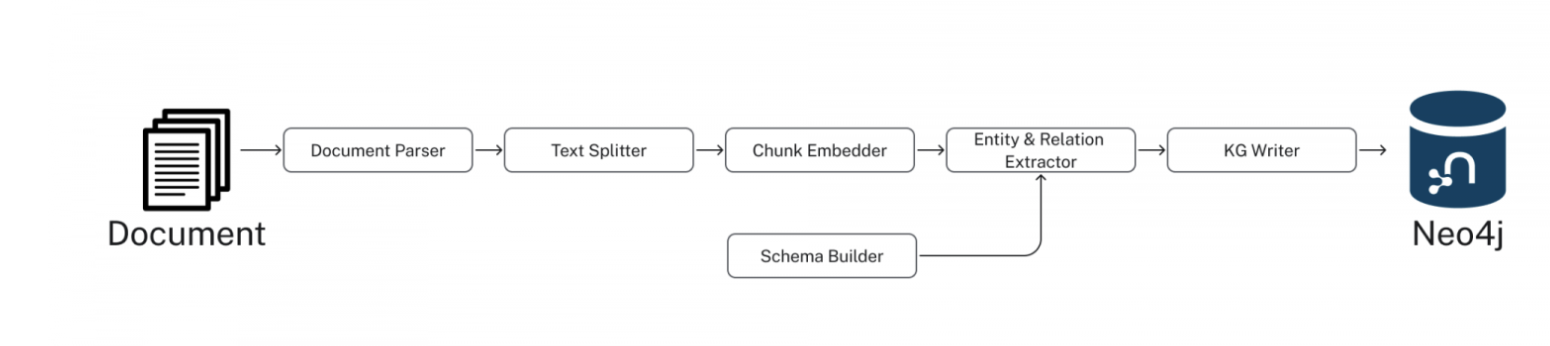 With knowledge graphs, unstructured text is passed through an LLM to construct graphs of entities and their relationships, which are then stored in a graph database like Neo4j (see image above). If a user asks a question, Neo4j is queried first and then the results are passed to an LLM (see image below). The results are explainable to the user and complex queries can be answered because of the relationships stored in the graph DB.
With knowledge graphs, unstructured text is passed through an LLM to construct graphs of entities and their relationships, which are then stored in a graph database like Neo4j (see image above). If a user asks a question, Neo4j is queried first and then the results are passed to an LLM (see image below). The results are explainable to the user and complex queries can be answered because of the relationships stored in the graph DB.
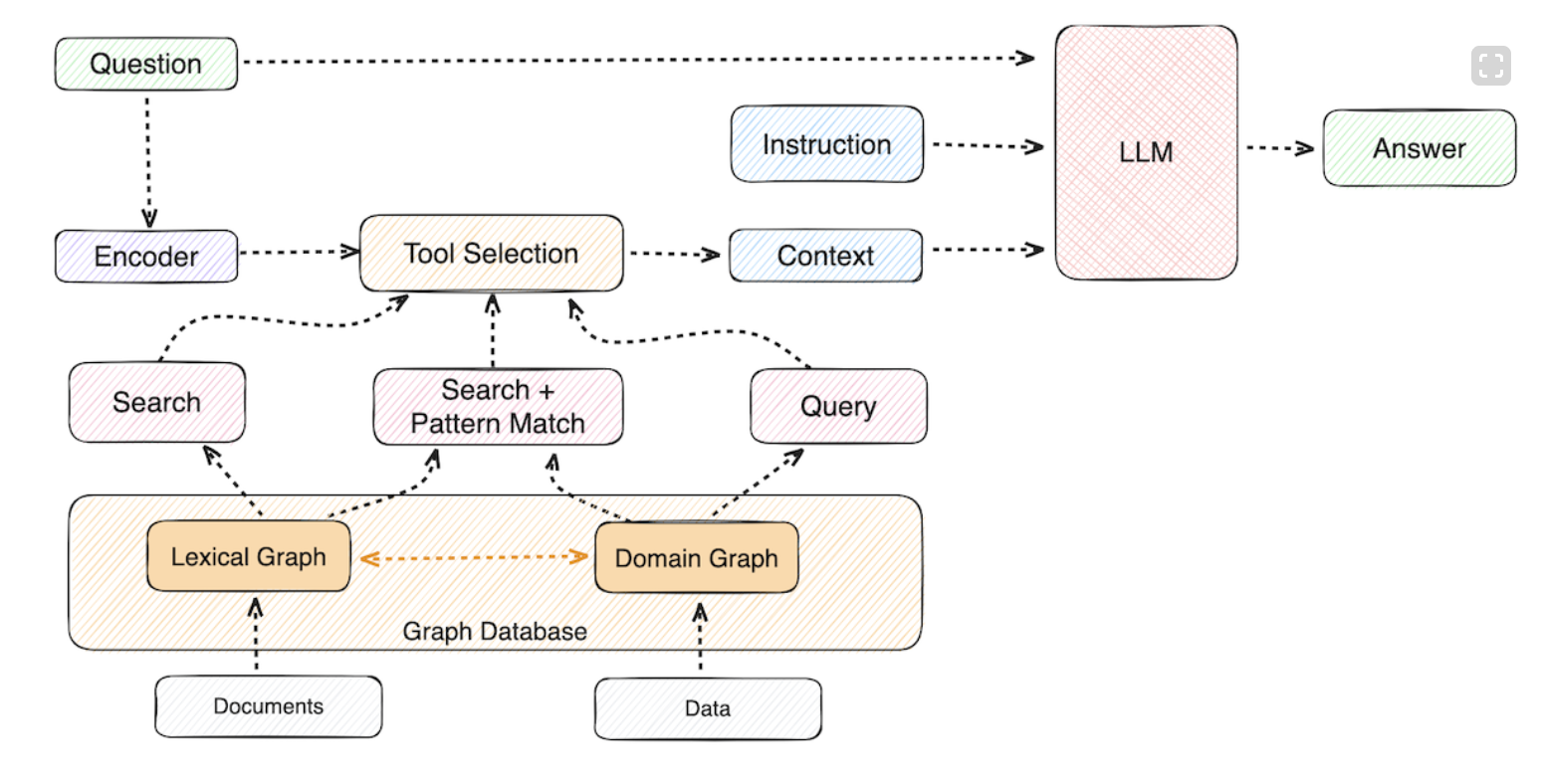
My guess is that Tetrix uses a hybrid approach, retrieving data first from the vector DB and then using each data point to further query knowledge graphs - those results are fed to the LLM. The results are traceable and explainable.
Other talks
The second talk was by PostHog about technical writing in the age of LLMs. These days, devs don’t directly refer to docs while building APIs. Instead, they often use LLMs to parse the docs first. Hence, technical writers have to change the way they write documents. Adding more examples, being more opinionated and covering all edge cases are the recommended approaches. Also, the speaker mentioned that Firebase docs were great because they’d often contain implementation plans which made LLMs more effective.
The third talk was by IT Methods which was vague and incomprehensible.
Lastly, a startup called Weave demo-ed their product for measuring developer productivity. They used AI to categorize the type of work (bugs vs features) and also figure out if AI was making the org more effective. Their quality metric was the amount of rework on the same set of files within 3 months.